Pipeline en échec, agent offline, builds qui plantent sans raison apparente. Le diagnostic tombe : disque saturé à 99%. Un classique des agents self-hosted qu'on peut régler définitivement.
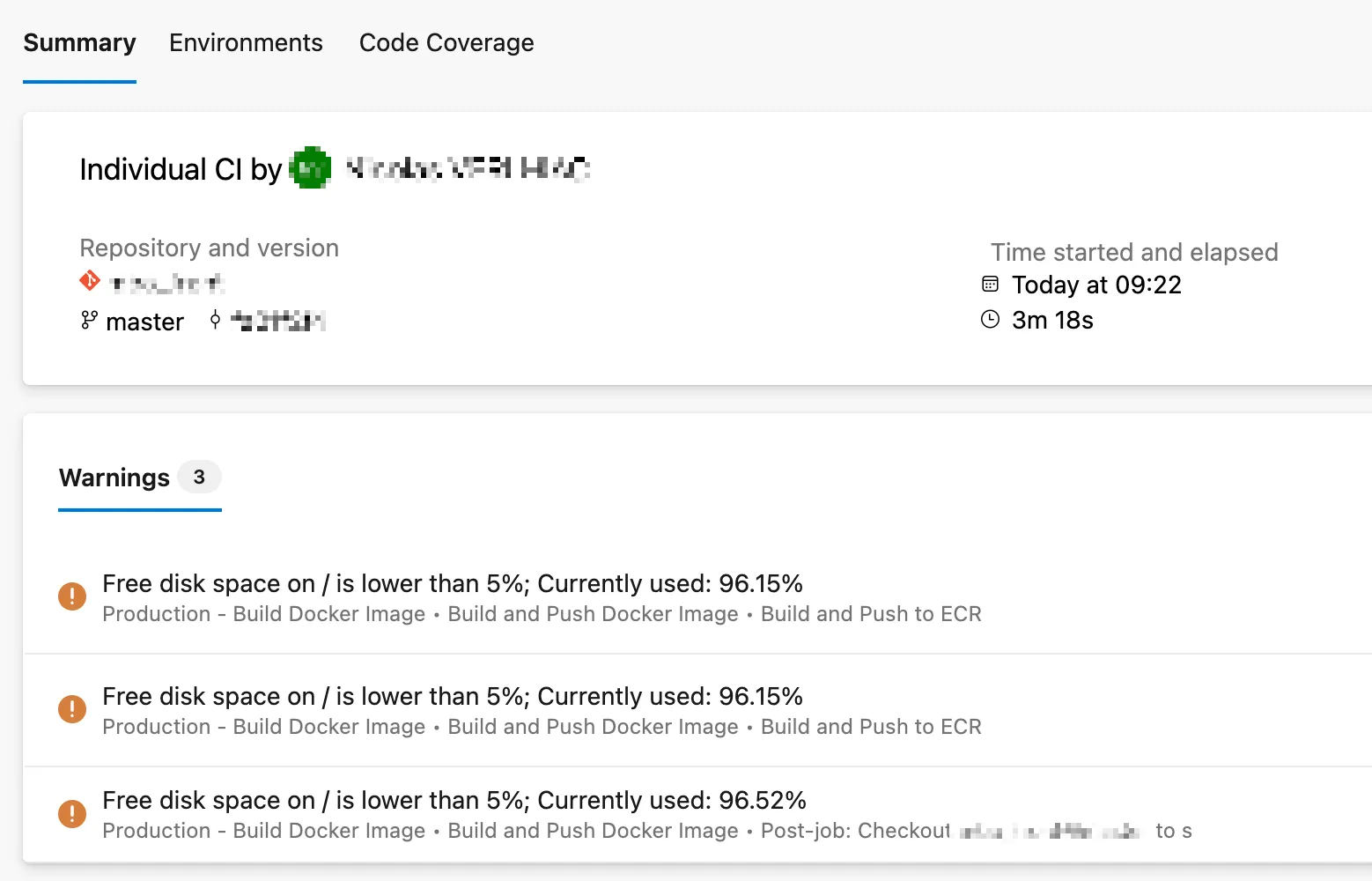
Vendredi matin, le pipeline de déploiement échoue. L’agent Azure DevOps self-hosted ne répond plus. Un rapide df -h sur l’instance EC2 révèle le verdict :
Filesystem Size Used Avail Use% Mounted on
/dev/root 67G 66G 670M 99% /99% d’utilisation. Plus assez d’espace pour que Docker pull une image ou que Git clone un repo. Le pipeline est bloqué.
Un agent Azure DevOps self-hosted qui tourne depuis quelques semaines finit souvent avec un disque plein. Le coupable n’est pas Azure DevOps, mais ce qu’il laisse derrière lui.
Trouver le coupable
Sur un agent de build, les suspects sont toujours les mêmes :
docker system dfTYPE TOTAL ACTIVE SIZE RECLAIMABLE
Images 202 0 48.91GB 48.91GB (100%)
Containers 0 0 0B 0B
Build Cache 87 0 13.29GB 13.29GB (100%)62 Go d’images Docker et de cache. 202 images accumulées, zéro en cours d’utilisation.
Chaque pipeline qui build une image Docker la laisse sur le serveur. build-7667, build-7546, build-7329… Elles s’empilent, semaine après semaine, sans que personne ne les supprime.
docker images --format 'table {{.Repository}}\t{{.Tag}}\t{{.CreatedSince}}' | head -10REPOSITORY TAG CREATED
1111111111111.dkr.ecr.eu-west-3.amazonaws.com/app build-7746 2 hours ago
1111111111111.dkr.ecr.eu-west-3.amazonaws.com/app build-7667 2 days ago
1111111111111.dkr.ecr.eu-west-3.amazonaws.com/app build-7329 2 weeks ago
1111111111111.dkr.ecr.eu-west-3.amazonaws.com/app build-6465 6 weeks agoDes images de 6 semaines. Inutiles, mais toujours là.
Pourquoi Azure DevOps ne nettoie pas
Azure DevOps gère la rétention des artefacts et des runs dans le cloud. Mais ce qui se passe sur votre agent self-hosted lui échappe :
| Ce qu’Azure DevOps gère | Ce qu’il ne gère pas |
|---|---|
| Rétention des runs et artefacts | Images Docker locales |
Nettoyage du workspace (option clean) | Cache Docker |
| Logs des pipelines | Espace disque de l’agent |
L’agent est votre machine. Son entretien vous revient.
La solution : nettoyage automatique
Un cron job quotidien qui supprime les images de plus de 7 jours règle le problème définitivement.
Créer le script
sudo tee /etc/cron.daily/docker-cleanup << 'EOF'
#!/bin/bash
# Nettoyage Docker - conservation 7 jours (168h)
docker image prune -a --filter "until=168h" -f >> /var/log/docker-cleanup.log 2>&1
docker builder prune --filter "until=168h" -f >> /var/log/docker-cleanup.log 2>&1
docker volume prune -f >> /var/log/docker-cleanup.log 2>&1
EOF
sudo chmod +x /etc/cron.daily/docker-cleanupLe script s’exécute chaque jour via cron. Les images de moins de 7 jours sont conservées (utile pour un rollback rapide), les autres sont supprimées.
Nettoyage immédiat
Pour débloquer l’agent maintenant :
docker image prune -a --filter "until=168h" -f
docker builder prune --filter "until=168h" -f
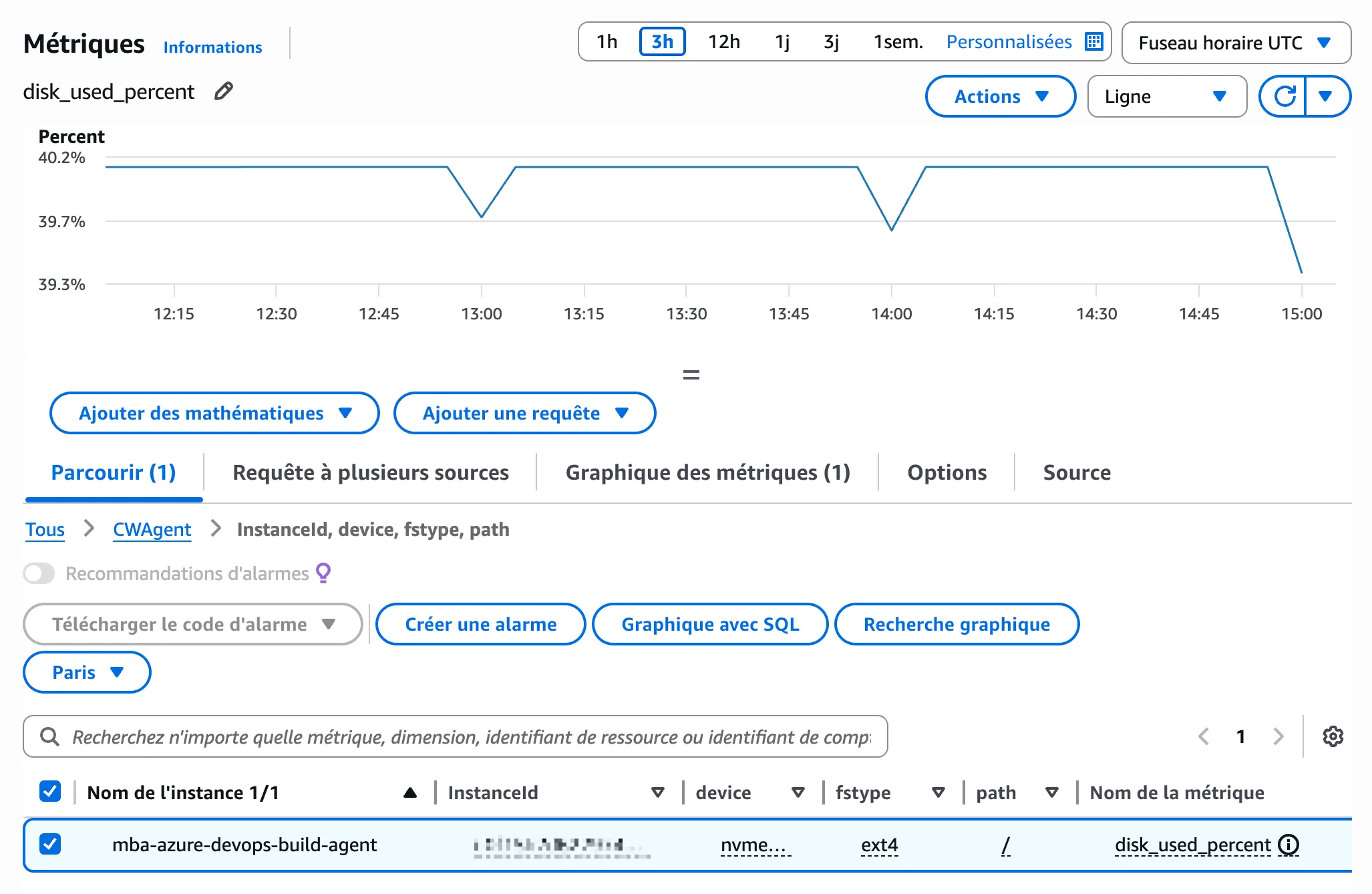
docker volume prune -fRésultat sur notre cas : 40 Go libérés. Le disque passe de 99% à 39%.
Ajuster la rétention
Adaptez la durée selon votre contexte :
| Situation | Rétention | Paramètre |
|---|---|---|
| Builds très fréquents, petit disque | 3 jours | until=72h |
| Usage standard | 7 jours | until=168h |
| Besoin de rollback fréquent | 14 jours | until=336h |
Ne plus se faire surprendre : monitoring
Le nettoyage automatique règle le problème Docker. Mais d’autres fichiers peuvent s’accumuler. Une alerte CloudWatch vous prévient avant que le disque ne sature.
Prérequis IAM
L’instance EC2 doit avoir un rôle IAM avec la policy CloudWatchAgentServerPolicy. Sans cela, l’agent ne peut pas envoyer les métriques :
# Ce message dans les logs indique un problème de permissions
NoCredentialProviders: no valid providers in chainAttachez un rôle via EC2 → Instance → Actions → Security → Modify IAM role.
Installer l’agent CloudWatch
# Avec wget
wget https://s3.amazonaws.com/amazoncloudwatch-agent/ubuntu/amd64/latest/amazon-cloudwatch-agent.deb
# Ou avec curl
curl -O https://s3.amazonaws.com/amazoncloudwatch-agent/ubuntu/amd64/latest/amazon-cloudwatch-agent.deb
sudo dpkg -i amazon-cloudwatch-agent.debConfigurer la métrique disque
Créez le fichier /opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.json :
{
"metrics": {
"metrics_collected": {
"disk": {
"measurement": ["used_percent"],
"resources": ["/"],
"ignore_file_system_types": ["tmpfs", "devtmpfs"]
}
},
"append_dimensions": {
"InstanceId": "${aws:InstanceId}"
}
}
}Puis chargez la configuration :
sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl \
-a fetch-config -m ec2 \
-c file:/opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.json -sCréer l’alarme
Dans CloudWatch → Alarms → Create alarm :
- Metric :
CWAgent→disk_used_percent - Threshold : Greater than 80 (ou 50 si vous préférez anticiper davantage)
- Notification : votre SNS topic
Coût : ~0.40$/mois pour la métrique et l’alarme.
Récapitulatif
# Diagnostic
df -h
docker system df
# Nettoyage immédiat
docker image prune -a --filter "until=168h" -f
docker builder prune --filter "until=168h" -f
docker volume prune -f
# Automatisation
sudo tee /etc/cron.daily/docker-cleanup << 'EOF'
#!/bin/bash
docker image prune -a --filter "until=168h" -f >> /var/log/docker-cleanup.log 2>&1
docker builder prune --filter "until=168h" -f >> /var/log/docker-cleanup.log 2>&1
docker volume prune -f >> /var/log/docker-cleanup.log 2>&1
EOF
sudo chmod +x /etc/cron.daily/docker-cleanup
# Monitoring (CloudWatch Agent + alarme à 80%)Un agent de build self-hosted demande un minimum d’entretien. Le nettoyage automatique des images Docker et une alerte sur l’espace disque transforment un problème récurrent en non-sujet.
10 minutes de setup, zéro pipeline bloqué.