Disque plein à 96% sur votre runner CI/CD ou serveur de prod ? Pas de panique. AWS permet d'étendre un volume EBS à chaud, sans arrêter l'instance. Voici la procédure complète.
Un serveur EC2 qui affiche 96% d’utilisation disque, c’est le genre d’alerte qui fait accélérer le rythme cardiaque. Bonne nouvelle : depuis 2017, AWS permet d’étendre les volumes EBS à chaud, sans downtime ni redémarrage.
L’extension à chaud d’un volume EBS est une opération courante et sans risque, à condition de suivre les étapes dans l’ordre.
Prérequis et précautions
Avant de modifier quoi que ce soit :
Créez un snapshot du volume. C’est rapide, ça ne coûte presque rien, et ça peut sauver votre journée si quelque chose tourne mal.
# Identifier le volume à étendre
df -h
# Exemple de sortie
Filesystem Size Used Avail Use% Mounted on
/dev/root 29G 27G 1.2G 96% /Dans la console AWS, le snapshot se crée en quelques clics : EC2 → Volumes → Actions → Créer un instantané.
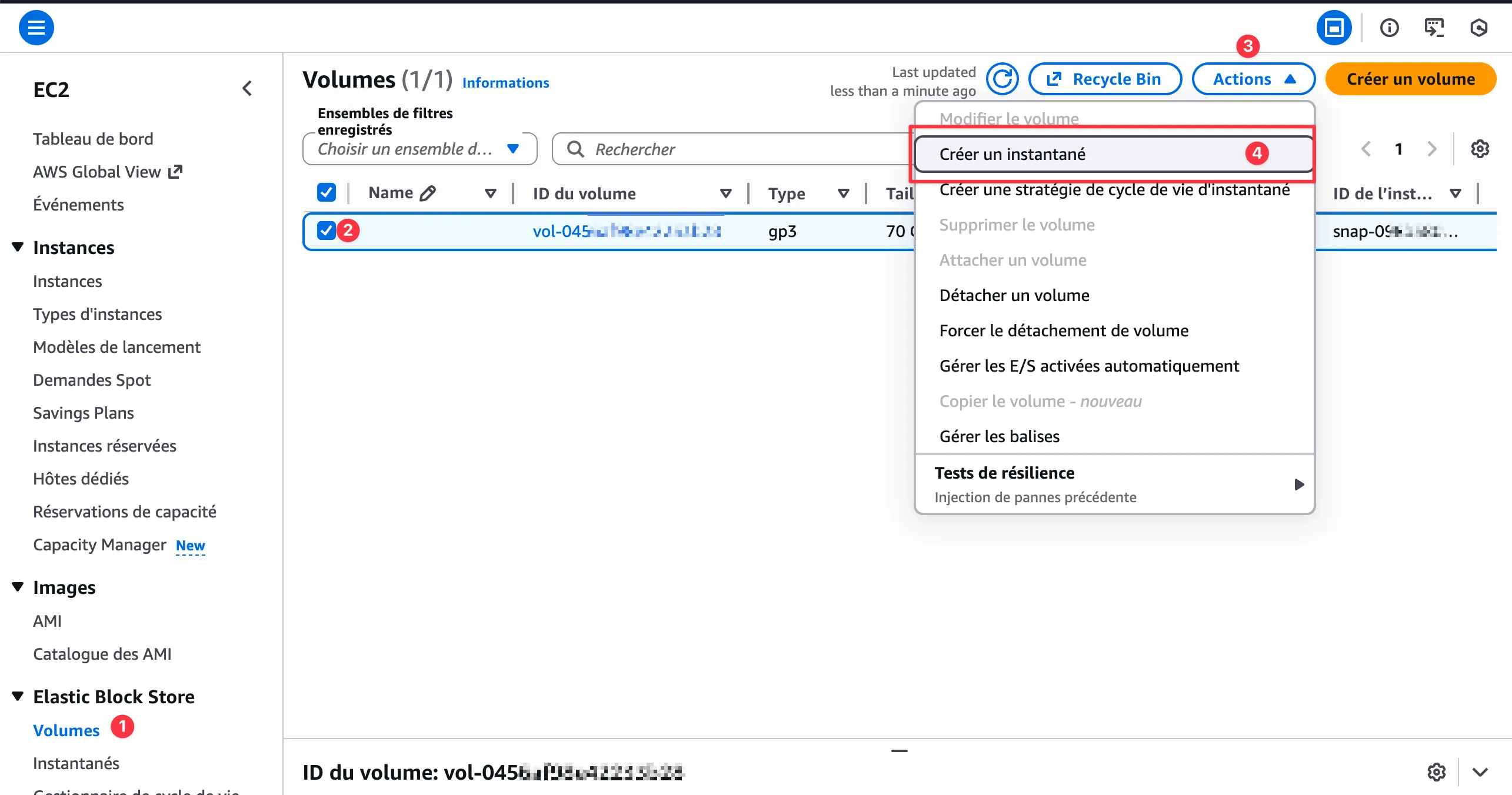
Étape 1 : Étendre le volume côté AWS
Via la Console AWS
- Ouvrez la console EC2 → Elastic Block Store → Volumes
- Sélectionnez le volume à étendre
- Actions → Modify Volume
- Entrez la nouvelle taille (ex : 70 Go au lieu de 30 Go)
- Confirmez la modification
Le volume passe en état modifying, puis optimizing. L’optimisation peut prendre du temps (parfois plusieurs heures pour les gros volumes), mais le nouvel espace est disponible dès que l’état quitte modifying.
Via AWS CLI
# Identifier l'ID du volume
aws ec2 describe-volumes --filters "Name=attachment.instance-id,Values=i-xxxxxxxxx" \
--query "Volumes[*].{ID:VolumeId,Size:Size,State:State}" --output table
# Étendre le volume à 70 Go
aws ec2 modify-volume --volume-id vol-xxxxxxxxx --size 70
# Suivre la progression
aws ec2 describe-volumes-modifications --volume-id vol-xxxxxxxxx \
--query "VolumesModifications[*].{Progress:Progress,State:ModificationState}" --output tableÉtape 2 : Étendre la partition Linux
Une fois le volume étendu côté AWS, Linux voit le nouvel espace mais la partition ne l’utilise pas encore.
Vérifier que le nouvel espace est visible
lsblk# Sortie attendue : le disque affiche la nouvelle taille
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
nvme0n1 259:0 0 70G 0 disk
├─nvme0n1p1 259:1 0 29G 0 part / # ← Partition encore à 29G
├─nvme0n1p14 259:2 0 4M 0 part
├─nvme0n1p15 259:3 0 106M 0 part /boot/efi
└─nvme0n1p16 259:4 0 913M 0 part /bootLe disque nvme0n1 fait 70G, mais la partition nvme0n1p1 est toujours à 29G.
Étendre la partition avec growpart
# Installer growpart si nécessaire (généralement déjà présent)
sudo apt install cloud-guest-utils # Debian/Ubuntu
sudo yum install cloud-utils-growpart # Amazon Linux/RHEL
# Étendre la partition 1 du disque nvme0n1
sudo growpart /dev/nvme0n1 1# Sortie attendue
CHANGED: partition=1 start=227328 old: size=60887999 end=61115327 new: size=146673631 end=146900959Vérifiez avec lsblk que la partition a bien été étendue.
Étape 3 : Étendre le système de fichiers
La partition est étendue, mais le filesystem doit encore être agrandi pour utiliser l’espace.
Identifier le type de filesystem
df -Th /Filesystem Type Size Used Avail Use% Mounted on
/dev/root ext4 29G 27G 1.2G 96% /Pour ext4 (Ubuntu, Debian)
sudo resize2fs /dev/nvme0n1p1# Sortie attendue
resize2fs 1.46.5 (30-Dec-2021)
Filesystem at /dev/nvme0n1p1 is mounted on /; on-line resizing required
old_desc_blocks = 4, new_desc_blocks = 9
The filesystem on /dev/nvme0n1p1 is now 18334203 (4k) blocks long.Pour xfs (Amazon Linux, RHEL, CentOS)
sudo xfs_growfs /XFS utilise le point de montage (/) plutôt que le device.
Vérification finale
df -h /Filesystem Size Used Avail Use% Mounted on
/dev/root 67G 27G 41G 40% /De 96% à 40% d’utilisation. Mission accomplie.
Cas particuliers
Volume root vs volume data
La procédure est identique pour les volumes root (/) et les volumes data montés séparément. La seule différence : pour un volume data, vous pouvez le démonter, ce qui simplifie certaines opérations.
Disques nommés /dev/xvda vs /dev/nvme0n1
Les instances récentes (Nitro) utilisent le naming nvme. Les anciennes instances utilisent xvda, xvdb, etc.
# Instances Nitro (t3, m5, c5, etc.)
sudo growpart /dev/nvme0n1 1
sudo resize2fs /dev/nvme0n1p1
# Anciennes instances (t2, m4, etc.)
sudo growpart /dev/xvda 1
sudo resize2fs /dev/xvda1Volume sans partition (rare)
Certains volumes n’ont pas de table de partition — le filesystem est directement sur le device. Dans ce cas, sautez l’étape growpart :
# Vérifier : si lsblk ne montre pas de partition enfant
lsblk
# nvme1n1 259:1 0 100G 0 disk /data ← Pas de partition
# Étendre directement le filesystem
sudo resize2fs /dev/nvme1n1 # ext4
sudo xfs_growfs /data # xfsAutomatiser la surveillance
Pour éviter de vous retrouver à nouveau à 96%, mettez en place une alerte CloudWatch :
# Créer une alarme CloudWatch pour l'espace disque
aws cloudwatch put-metric-alarm \
--alarm-name "DiskSpaceAlert-i-xxxxxxxxx" \
--metric-name "disk_used_percent" \
--namespace "CWAgent" \
--statistic Average \
--period 300 \
--threshold 80 \
--comparison-operator GreaterThanThreshold \
--dimensions Name=InstanceId,Value=i-xxxxxxxxx Name=path,Value=/ \
--evaluation-periods 2 \
--alarm-actions arn:aws:sns:eu-west-1:123456789:alertsCela nécessite l’agent CloudWatch installé sur l’instance. Alternativement, un simple cron avec notification :
# /etc/cron.daily/check-disk-space
#!/bin/bash
THRESHOLD=80
USAGE=$(df / | awk 'NR==2 {print $5}' | tr -d '%')
if [ "$USAGE" -gt "$THRESHOLD" ]; then
echo "Alerte: utilisation disque à ${USAGE}%" | mail -s "Disk Alert $(hostname)" admin@example.com
fiRécapitulatif des commandes
# 1. Snapshot (console AWS ou CLI)
aws ec2 create-snapshot --volume-id vol-xxx --description "Backup avant extension"
# 2. Étendre le volume (console AWS ou CLI)
aws ec2 modify-volume --volume-id vol-xxx --size 70
# 3. Vérifier que Linux voit le nouvel espace
lsblk
# 4. Étendre la partition
sudo growpart /dev/nvme0n1 1
# 5. Étendre le filesystem
sudo resize2fs /dev/nvme0n1p1 # ext4
# ou
sudo xfs_growfs / # xfs
# 6. Vérifier
df -h /L’extension de volume EBS à chaud est une opération devenue banale dans l’écosystème AWS. Pas de downtime, pas de migration de données, juste quelques commandes. Le plus long reste souvent l’optimisation côté AWS, qui tourne en arrière-plan sans impact sur vos opérations.
Pensez au snapshot avant, pensez au monitoring après. Entre les deux, l’opération ne prend que quelques minutes.